MinHash LSH
Suppose you have a very large collection of sets. Giving a query, which is also a set, you want to find sets in your collection that have Jaccard similarities above certain threshold, and you want to do it with many other queries. To do this efficiently, you can create a MinHash for every set, and when a query comes, you compute the Jaccard similarities between the query MinHash and all the MinHash of your collection, and return the sets that satisfy your threshold.
The said approach is still an O(n) algorithm, meaning the query cost increases linearly with respect to the number of sets. A popular alternative is to use Locality Sensitive Hashing (LSH) index. LSH can be used with MinHash to achieve sub-linear query cost - that is a huge improvement. The details of the algorithm can be found in Chapter 3, Mining of Massive Datasets.
This package includes the classic version of MinHash LSH. It is important to note that the query does not give you the exact result, due to the use of MinHash and LSH. There will be false positives - sets that do not satisfy your threshold but returned, and false negatives - qualifying sets that are not returned. However, the property of LSH assures that sets with higher Jaccard similarities always have higher probabilities to get returned than sets with lower similarities. Moreover, LSH can be optimized so that there can be a “jump” in probability right at the threshold, making the qualifying sets much more likely to get returned than the rest.
from datasketch import MinHash, MinHashLSH
set1 = set(['minhash', 'is', 'a', 'probabilistic', 'data', 'structure', 'for',
'estimating', 'the', 'similarity', 'between', 'datasets'])
set2 = set(['minhash', 'is', 'a', 'probability', 'data', 'structure', 'for',
'estimating', 'the', 'similarity', 'between', 'documents'])
set3 = set(['minhash', 'is', 'probability', 'data', 'structure', 'for',
'estimating', 'the', 'similarity', 'between', 'documents'])
m1 = MinHash(num_perm=128)
m2 = MinHash(num_perm=128)
m3 = MinHash(num_perm=128)
for d in set1:
m1.update(d.encode('utf8'))
for d in set2:
m2.update(d.encode('utf8'))
for d in set3:
m3.update(d.encode('utf8'))
# Create LSH index
lsh = MinHashLSH(threshold=0.5, num_perm=128)
lsh.insert("m2", m2)
lsh.insert("m3", m3)
result = lsh.query(m1)
print("Approximate neighbours with Jaccard similarity > 0.5", result)
The Jaccard similarity threshold must be set at initialization, and
cannot be changed. So does the number of permutation functions (num_perm) parameter.
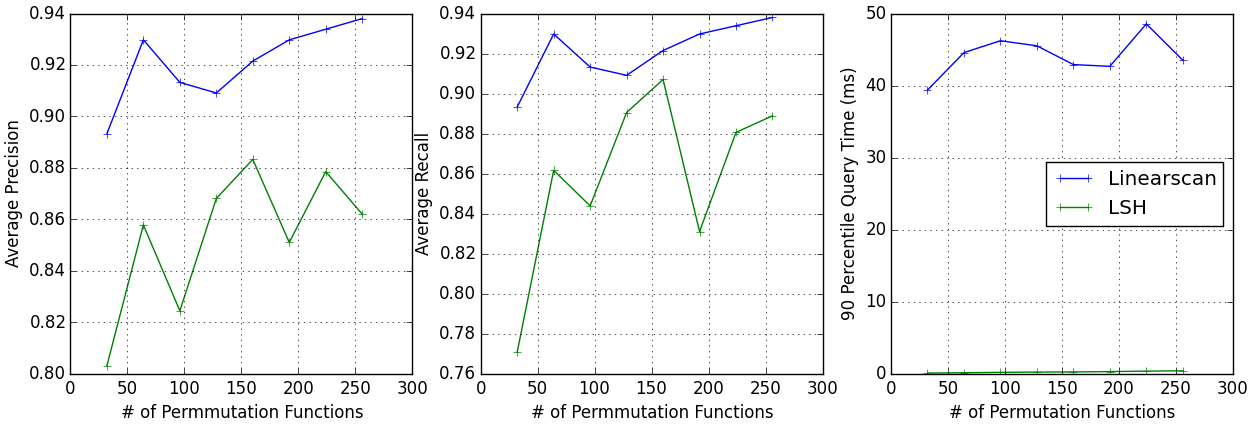
Similar to MinHash, more permutation functions improves the accuracy,
but also increases query cost, since more processing is required as the
MinHash gets bigger.
I experimented with the 20 News Group
Dataset,
which has an average cardinality of 193 (3-shingles). The average
recall, average precision, and 90 percentile query time vs. number of permutation
functions
are plotted below.
See the benchmark
directory in the source code repository for more experiment and
plotting code.
You can merge two MinHashLSH indexes to create a union index using the merge method. This
makes MinHashLSH useful in parallel processing.
# This merges the lsh1 with lsh2.
lsh1.merge(lsh2)
There are other optional parameters that can be used to tune the index.
See the documentation of datasketch.MinHashLSH for details.
MinHash LSH does not support Top-K queries. See MinHash LSH Forest for an alternative. In addition, Jaccard similarity may not be the best measure if your intention is to find sets having high intersection with the query. For intersection search, see MinHash LSH Ensemble.
MinHash LSH at scale
MinHash LSH supports using Redis as the storage layer for handling large index and providing optional persistence as part of a production environment. The Redis storage option can be configured using:
from datasketch import MinHashLSH
lsh = MinHashLSH(
threshold=0.5, num_perm=128, storage_config={
'type': 'redis',
'redis': {'host': 'localhost', 'port': 6379},
}
)
To insert a large number of MinHashes in sequence, it is advisable to use an insertion session. This reduces the number of network calls during bulk insertion.
data_list = [("m1", m1), ("m2", m2), ("m3", m3)]
with lsh.insertion_session() as session:
for key, minhash in data_list:
session.insert(key, minhash)
Note that querying the LSH object during an open insertion session may result in inconsistency.
MinHash LSH also supports a Cassandra cluster as a storage layer. Using a long-term storage for your LSH addresses all use cases where the application needs to continuously update the LSH object (for example when you use MinHash LSH to incrementally cluster documents).
The Cassandra storage option can be configured as follows:
from datasketch import MinHashLSH
lsh = MinHashLSH(
threshold=0.5, num_perm=128, storage_config={
'type': 'cassandra',
'cassandra': {
'seeds': ['127.0.0.1'],
'keyspace': 'lsh_test',
'replication': {
'class': 'SimpleStrategy',
'replication_factor': '1',
},
'drop_keyspace': False,
'drop_tables': False,
}
}
)
The parameter seeds specifies the list of seed nodes that can be contacted to connect to the Cassandra cluster. Options keyspace and replication specify the parameters to be used when creating a keyspace (if not already existing). If you want to force creation of either tables or keyspace (and thus DROP existing ones), set drop_tables and drop_keyspace options to True.
Like the Redis counterpart, you can use insert sessions to reduce the number of network calls during bulk insertion.
Connecting to Existing MinHash LSH
If you are using an external storage layer (e.g., Redis) for your LSH, you can share it across multiple processes. Ther are two ways to do it:
The recommended way is to use “pickling”. The MinHash LSH object is serializable so you can call pickle:
import pickle
# Create your LSH object
lsh = ...
# Serialize the LSH
data = pickle.dumps(lsh)
# Now you can pass it as an argument to a forked process or simply save it
# in an external storage.
# In a different process, deserialize the LSH
lsh = pickle.loads(data)
Using pickle allows you to preserve everything you need to know about the LSH such as various parameter settings in a single location.
Alternatively you can specify basename in the storage config when you first creating the LSH. For example:
# For Redis.
lsh = MinHashLSH(
threshold=0.5, num_perm=128, storage_config={
'type': 'redis',
'basename': b'unique_name_6ac4fg',
'redis': {'host': 'localhost', 'port': 6379},
}
)
# For Cassandra.
lsh = MinHashLSH(
threashold=0.5, num_perm=128, storage_config={
'type': 'cassandra',
'basename': b'unique_name',
'cassandra': {
'seeds': ['127.0.0.1'],
'keyspace': 'lsh_test',
'replication': {
'class': 'SimpleStrategy',
'replication_factor': '1',
},
'drop_keyspace': False,
'drop_tables': False,
}
}
)
The basename will be used to generate key prefixes in the storage layer to uniquely identify data associated with this LSH. Thus, if you create a new LSH object with the same basename, you will be using the same underlying data in the storage layer associated with the old LSH.
If you don’t specify basename, MinHash LSH will generate a random string as the base name, and collision is extremely unlikely.
Asynchronous MinHash LSH at scale
Note
The module supports Python version >=3.6, and is currently experimental. So the interface may change slightly in the future.
This module may be useful if you want to process millions of text documents in streaming/batch mode using asynchronous RESTful API (for example, aiohttp) for clustering tasks, and maximize the throughput of your service.
We currently provide asynchronous MongoDB storage (python motor package) and Redis storage.
For sharing across different Python processes see MinHash LSH at scale.
The Asynchronous MongoDB storage option can be configured using:
Usual way:
from datasketch.experimental.aio.lsh import AsyncMinHashLSH
from datasketch import MinHash
_storage = {'type': 'aiomongo', 'mongo': {'host': 'localhost', 'port': 27017, 'db': 'lsh_test'}}
async def func():
lsh = await AsyncMinHashLSH(storage_config=_storage, threshold=0.5, num_perm=16)
m1 = MinHash(16)
m1.update('a'.encode('utf8'))
m2 = MinHash(16)
m2.update('b'.encode('utf8'))
await lsh.insert('a', m1)
await lsh.insert('b', m2)
print(await lsh.query(m1))
print(await lsh.query(m2))
lsh.close()
Context Manager style:
from datasketch.experimental.aio.lsh import AsyncMinHashLSH
from datasketch import MinHash
_storage = {'type': 'aiomongo', 'mongo': {'host': 'localhost', 'port': 27017, 'db': 'lsh_test'}}
async def func():
async with AsyncMinHashLSH(storage_config=_storage, threshold=0.5, num_perm=16) as lsh:
m1 = MinHash(16)
m1.update('a'.encode('utf8'))
m2 = MinHash(16)
m2.update('b'.encode('utf8'))
await lsh.insert('a', m1)
await lsh.insert('b', m2)
print(await lsh.query(m1))
print(await lsh.query(m2))
To configure Asynchronous MongoDB storage that will connect to a replica set of three nodes, use:
_storage = {'type': 'aiomongo', 'mongo': {'replica_set': 'rs0', 'replica_set_nodes': 'node1:port1,node2:port2,node3:port3'}}
To connect to a cloud Mongo Atlas cluster (or any other arbitrary mongodb URI):
_storage = {'type': 'aiomongo', 'mongo': {'url': 'mongodb+srv://user:pass@server-ybq4y.mongodb.net/db'}}
If you want to pass additional params to the Mongo client <http://api.mongodb.com/python/current/api/pymongo/mongo_client.html> constructor, just put them in the mongo.args object in the storage config (example usage to configure X509 authentication):
_storage = {
'type': 'aiomongo',
'mongo':
{
...,
'args': {
'ssl': True,
'ssl_ca_certs': 'root-ca.pem',
'ssl_pem_passphrase': 'password',
'ssl_certfile': 'certfile.pem',
'authMechanism': "MONGODB-X509",
'username': "username"
}
}
}
To create index for a large number of MinHashes using asynchronous MinHash LSH.
from datasketch.experimental.aio.lsh import AsyncMinHashLSH
from datasketch import MinHash
def chunk(it, size):
it = iter(it)
return iter(lambda: tuple(islice(it, size)), ())
_chunked_str = chunk((random.choice(string.ascii_lowercase) for _ in range(10000)), 4)
seq = frozenset(chain((''.join(s) for s in _chunked_str), ('aahhb', 'aahh', 'aahhc', 'aac', 'kld', 'bhg', 'kkd', 'yow', 'ppi', 'eer')))
objs = [MinHash(16) for _ in range(len(seq))]
for e, obj in zip(seq, objs):
for i in e:
obj.update(i.encode('utf-8'))
data = [(e, m) for e, m in zip(seq, objs)]
_storage = {'type': 'aiomongo', 'mongo': {'host': 'localhost', 'port': 27017, 'db': 'lsh_test'}}
async def func():
async with AsyncMinHashLSH(storage_config=_storage, threshold=0.5, num_perm=16) as lsh:
async with lsh.insertion_session(batch_size=1000) as session:
fs = (session.insert(key, minhash, check_duplication=False) for key, minhash in data)
await asyncio.gather(*fs)
To bulk remove keys from LSH index using asynchronous MinHash LSH.
from datasketch.experimental.aio.lsh import AsyncMinHashLSH
from datasketch import MinHash
def chunk(it, size):
it = iter(it)
return iter(lambda: tuple(islice(it, size)), ())
_chunked_str = chunk((random.choice(string.ascii_lowercase) for _ in range(10000)), 4)
seq = frozenset(chain((''.join(s) for s in _chunked_str), ('aahhb', 'aahh', 'aahhc', 'aac', 'kld', 'bhg', 'kkd', 'yow', 'ppi', 'eer')))
objs = [MinHash(16) for _ in range(len(seq))]
for e, obj in zip(seq, objs):
for i in e:
obj.update(i.encode('utf-8'))
data = [(e, m) for e, m in zip(seq, objs)]
_storage = {'type': 'aiomongo', 'mongo': {'host': 'localhost', 'port': 27017, 'db': 'lsh_test'}}
async def func():
async with AsyncMinHashLSH(storage_config=_storage, threshold=0.5, num_perm=16) as lsh:
async with lsh.insertion_session(batch_size=1000) as session:
fs = (session.insert(key, minhash, check_duplication=False) for key, minhash in data)
await asyncio.gather(*fs)
async with lsh.delete_session(batch_size=3) as session:
fs = (session.remove(key) for key in keys_to_remove)
await asyncio.gather(*fs)
For AsyncMinHashLSH with redis, put your redis configurations in the storage config under the key redis.
_storage = {'type': 'aioredis', 'redis': {'host': '127.0.0.1', 'port': '6379'}}
The redis key in _storage is passed in redis.Redis directly, which mean you can pass custom args for redis yourself.